NVIDIA开源Lyra2.0框架,可从单张图像生成持久一致的大型3D场景,支持实时渲染与机器人仿真,为游戏开发和虚拟环境构建提供新工具。
英伟达发布Lyra2.0系统,通过单张照片即可生成延伸90米的大规模、高连贯性3D虚拟环境,解决了长距离相机路径下的图像失真问题。该技术突破标志着AI在3D空间理解与实时环境模拟领域取得重要进展,尤其满足了具身智能训练对高质量虚拟场景的迫切需求。
Google为AI助手Gemini推出重磅更新,新增交互式3D模型与动态模拟功能。用户询问涉及空间结构或物理规律的问题时,Gemini可生成可旋转、缩放的三维场景,如月球公转或双摆系统,支持滑块调节变量,以直观可视化方式帮助理解复杂概念。
Google Gemini 新增功能,可生成交互式3D模型与物理模拟场景,实现从文字回答到直观教学的跨越。用户提问涉及物理或三维空间时,AI提供动态窗口,支持自由拖动和多维视角调整,提升交互体验。
1.3B参数的图像转视频模型,用于生成3D一致的新场景视图
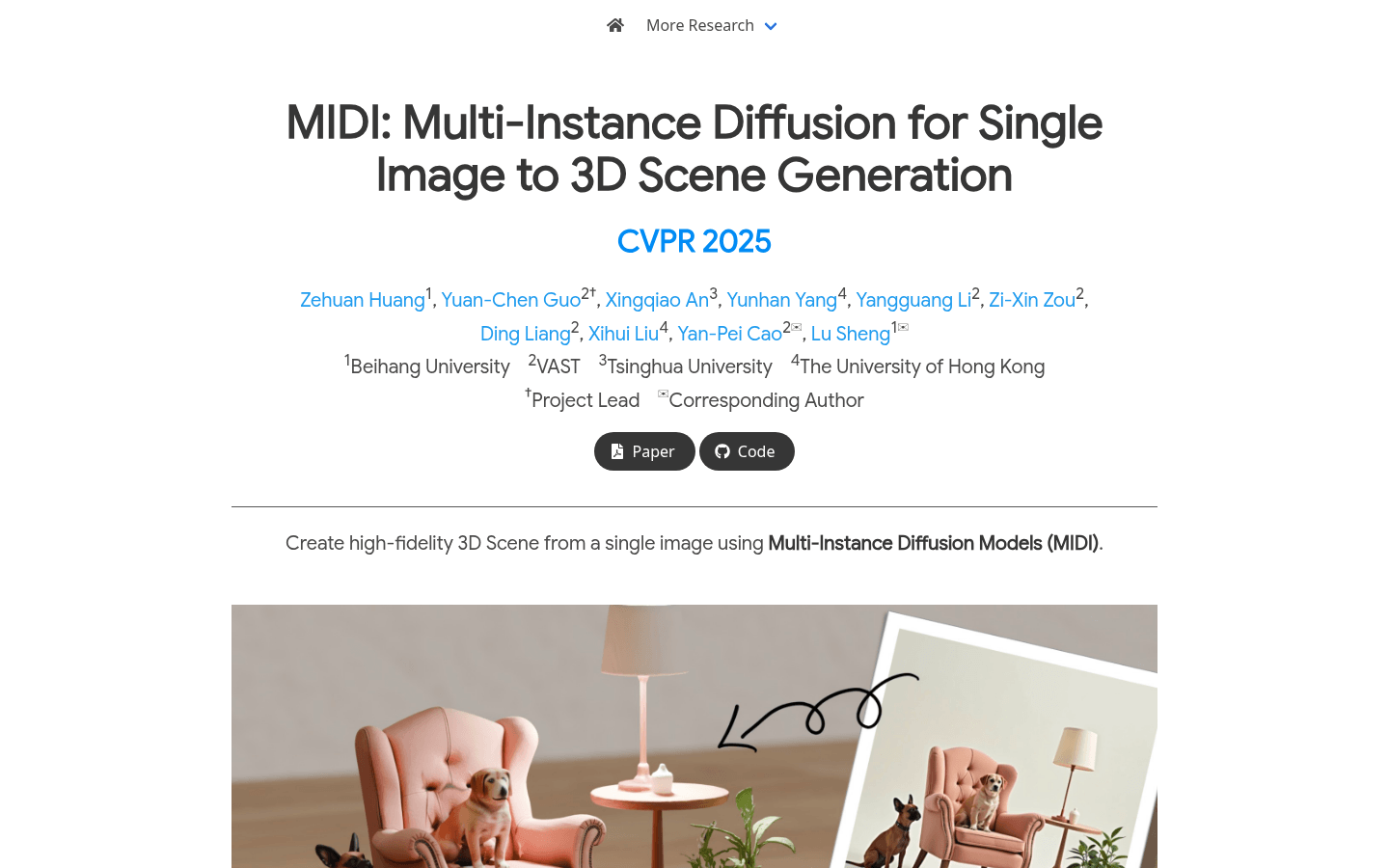
通过多实例扩散模型将单张图像生成高保真度的3D场景。
生成任何3D和4D场景的先进框架
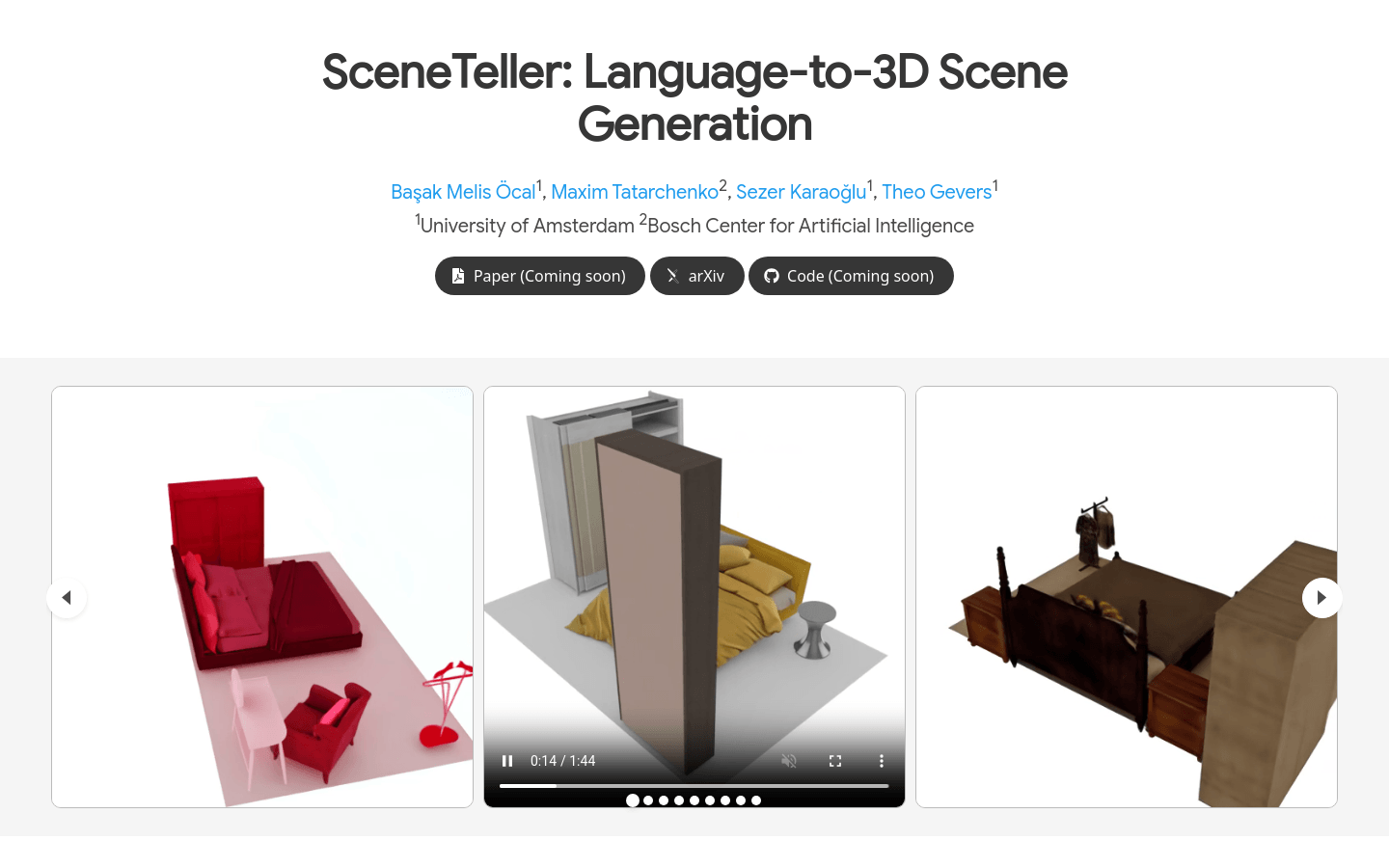
从文本描述生成高质量的3D室内场景。
Openai
$2.8
Input tokens/M
$11.2
Output tokens/M
1k
Context Length
Google
$0.49
$2.1
Xai
$1.4
$3.5
2k
$7.7
$30.8
200
-
Anthropic
$105
$525
$0.7
$7
$35
$17.5
$21
Alibaba
$4
$16
$6
$24
256
Baidu
128
Bytedance
$1.2
$3.6
4
$2
manycore-research
FLUX.1-Layout-ControlNet是SpatialGen框架的关键组件,是一个基于语义图像条件化的ControlNet模型。它能够根据文本描述生成2D图像,同时严格遵循输入语义图像的布局约束,主要用于3D室内场景合成。
lhjiang
AnySplat是一种先进的3D高斯散点渲染模型,能够从不同视角的图像高效生成高质量的3D场景。该模型具有快速推理能力和良好的泛化性能,为3D重建和渲染提供了创新的解决方案。
kvuong2711
AerialMegaDepth是一个专注于空地重建与视角合成的深度学习模型,能够从航拍图像中重建3D场景并生成新视角。
VAST-AI
MIDI是一款面向单图像生成组合式3D场景的生成模型。
Kai422kx
DAS3R是一种用于静态场景重建的3D模型,采用动态感知高斯泼溅技术,能够从图像生成高质量的3D重建效果。
strangerzonehf
基于LoRA微调的3D萌系卡通风格文本生成图像模型,可生成高质量的3D卡通角色和场景
基于LoRA微调的文本生成图像扩散模型,专注于生成等轴测3D风格的场景和物体
WizWhite
一个用于生成纸质微缩模型的LoRA模型,擅长创作平面纸板场景和3D纸质物件,具有复古风格。
davizca87
Coinmaker是一款专门用于生成硬币资产的LORA模型,基于SDXL 0.9训练而成。它能让电子游戏、渲染等场景中的硬币资产创建变得更加轻松、有趣且美观,尤其适用于3D投影和3D软件中的挤压建模。
该项目是一个连接Claude桌面应用与Unreal Engine 5.3的Python服务器,通过文本指令实现3D场景的创建与编辑,支持基础物体生成、蓝图调用和场景操作等功能。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)